When new concepts are added to an extension, or the definitions of existing concepts are modified, it is important that the extension is classified. Classification is performed for two main reason: firstly to ensure that logic errors are identified, and secondly to make it easy for users of the terminology (who may not necessarily have access to a classifier) to identify the full set of inferred relationships.
Classifying an extension requires combining the content in the extension modules with the content from all modules on which the extension modules depend (as defined by the Module Dependency Reference Set), including the modules from the International Edition. This ensures that the logical definition of all supertypes and attribute values of extension concepts can be used by the classifier in determining its inferences. The resulting set of inferred relationships (excluding redundant | is a| relationships) is then distributed in the Relationship file of the release.
There are, however, some limited situations in which classification may not be required in order to generate the (inferred) Relationship file for an extension. For example:
- The extension contains only reference sets, metadata concepts and/or descriptions
- The extension contains only primitive concepts for which the stated and inferred definition are equivalent
- Note: Some primitive concepts may infer new defining relationships during the classification process, so care should taken before assuming that classification is unnecessary for primitive content.
Purpose of Classification
The use of description logic as the formal foundation of SNOMED CT allows the semantics of clinical concepts to be represented unambiguously. Description logic also enables logical deduction in which additional information can be inferred from the explicit statements in the terminology. Classification is the process in which the formally stated definitions of each concept are used to compute the subsumption hierarchies and defining properties of each concept.
With each new release of SNOMED CT, the stated concept definitions are represented in the OWL Expression reference set, while the Relationship file, contains the full set of relationships that can be inferred using a classifier (excluding non-redundant | is a| relationships). Most consumers of the SNOMED CT will use the Relationship file (containing the inferred relationships). The OWL reference sets are primarily used by extension producers, but may also be used by terminology consumers that have access to a description logic classifier.
OWL Expression Reference Set
A release file that follows the OWL Expression Reference Set pattern and contains expressions that represent general statements about the SNOMED CT ontology and axioms that define SNOMED CT concepts.
Notes
- The OWL expression reference set contains two reference sets, the OWL ontology reference set and the OWL axiom reference set.
Related Links
- OWL ontology reference set
- OWL axiom reference set
- Release File Specification
Inferred Relationships
Inferred relationships are derived from the set of OWL axioms in the OWL Expression Reference Set, by applying a consistent set of logical rules to the definition which take account of the definitions of related concepts.
Several semantically equivalent views may be inferred from the same set of stated relationships. However, the SNOMED CT Relationship file is distributed using an inferred view known as the necessary normal form (NNF). This standard distribution view, includes all non-redundant | is a| relationships (between each concept and its proximal supertype), and the inferred concept definition of each concept (including all non-redundant defining relationships).
In the necessary normal view (NNF) appropriate subtype and attribute relationships are created to represent non-redundant axioms that are necessarily true capable of being represented using the relationship file format.
Some more advanced axioms (e.g. general class inclusions) can be represented in the OWL Expression Reference Set but cannot be represented in the Relationship File.
Example
This example is included to illustrate what happens during the classification process.
Consider the stated relationships shown below for the concepts | Appendectomy| and | Emergency appendectomy| . The concept definitions are represented in accordance with SNOMED CT Diagramming Guidelines.
Table 5.6.1.1-1: Example stated relationships
This diagram shows the stated definition of the concept | Appendectomy| . An | Appendectomy| is a procedure in which the appendix structure is excised. | Stated definition of |Appendectomy|
|
This diagram shows the stated definition of the concept | Emergency appendectomy| . An | Emergency appendectomy| is a procedure with a priority of emergency, in which the appendix structure is excised. | Stated definition of |Emergency appendectomy|
|
| This diagram shows a hierarchical view of the stated subtype relationships from the concepts above. | Stated subtype relationships
|
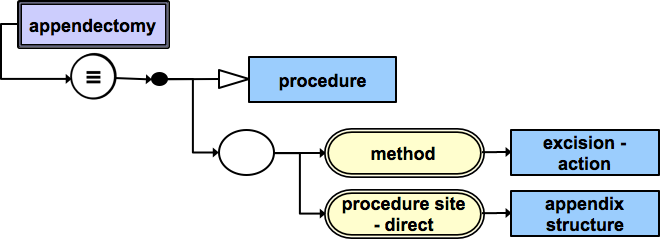
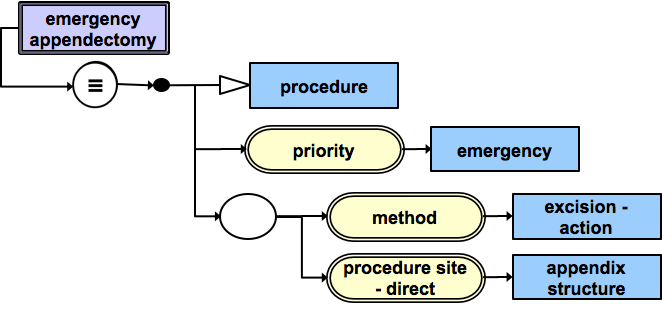
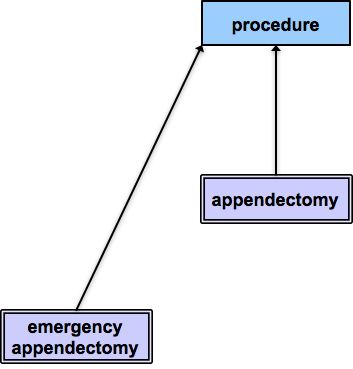
Table 5.6.1.1-2: Comparison of stated definitions
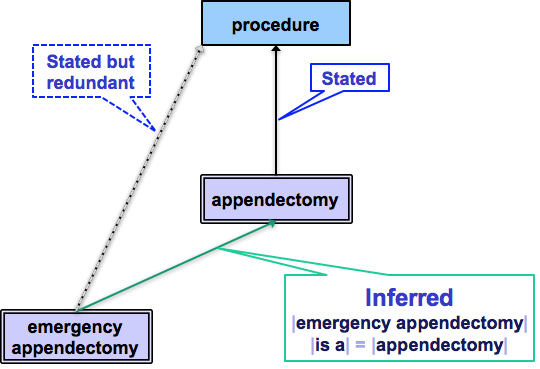
This diagram shows a comparison of the stated definitions for | Appendectomy| and | Emergency appendectomy| from above. The two definitions are identical, except for the additional defining relationship on | Emergency appendectomy| , which states that the priority is emergency. This means that a classifier can infer that | Emergency appendectomy| is a logical subtype of | Appendectomy| . |
|
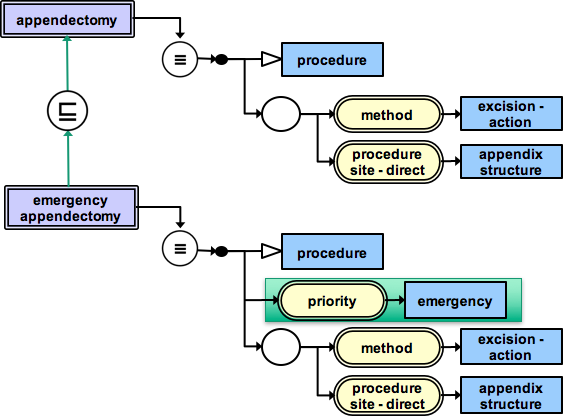
Table 5.6.1.1-3: Deriving the inferred relationships
This diagram shows that once the relationship | Emergency appendectomy| | is a| | Appendectomy| is inferred, the stated relationship | Emergency appendectomy| | is a| | Procedure| becomes redundant. |
|
Combining Modules for Classification
Classifying an extension requires combining the content in the extension modules with the content from all modules on which the extension modules depend (as defined by the Module Dependency Reference Set), including the modules from the International Edition. This ensures that the logical definition of all supertypes and attribute values of extension concepts can be used by the classifier in determining its inferences. The resulting set of inferred
The process of combining an extension with the content of the modules on which it depends is illustrated in Figure 5.6.1.1-1 below.
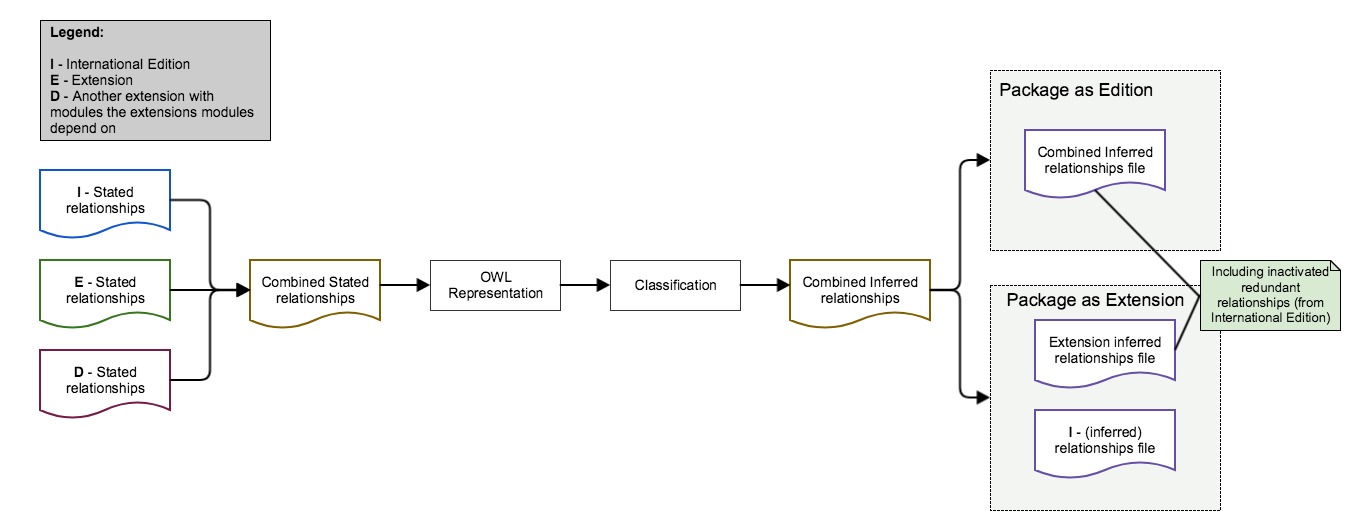
Figure 5.6.1.1-1: Creating inferred relationships for an extension
It is important that all inferred relationships present in the International Edition are also present in the combined inferred view. This means that the Relationship file in an extension's edition should be a superset of the Relationship file in the International Edition. In particular:- All relationships belonging to the International Edition should be retained in the extension edition, with the same moduleId and effectiveTime values
- All new inferred relationships created when classifying the extension should
- Be assigned to a module within the extension, and
- Use an effectiveTime which corresponds to the release date of the extension
If a situation occurs in which an inferred relationship from the International Edition becomes redundant in the extension edition (due to an intermediate concept being created in the extension), it may be necessary to inactivate the redundant international relationship in an extension module. For more information please refer to 5.4.4.3 Inactivate Relationship in an Extension.
For more information about options for packaging inferred extension relationships, please refer to 5.6.1.2 Packaging and File Naming.
Feedback
Overview
Content Tools
Apps